Overview
This project documents my journey building a multi-node Kubernetes cluster from scratch using budget-friendly mini-PCs and Raspberry Pi 5. The goal was to simulate real-world DevOps and SRE challenges in a homelab environment and have fun, since I enjoy working with computers.
Problem Statement
As an embedded systems engineer transitioning to cloud-native infrastructure, I needed a hands-on environment to:
- Develop and test infrastructure-as-code without expensive cloud bills
- Experience real Kubernetes operational challenges (node failures, resource constraints, networking issues)
- Build observability and monitoring solutions from scratch
- Prototype SRE techniques and incident response procedures
Architecture & Hardware
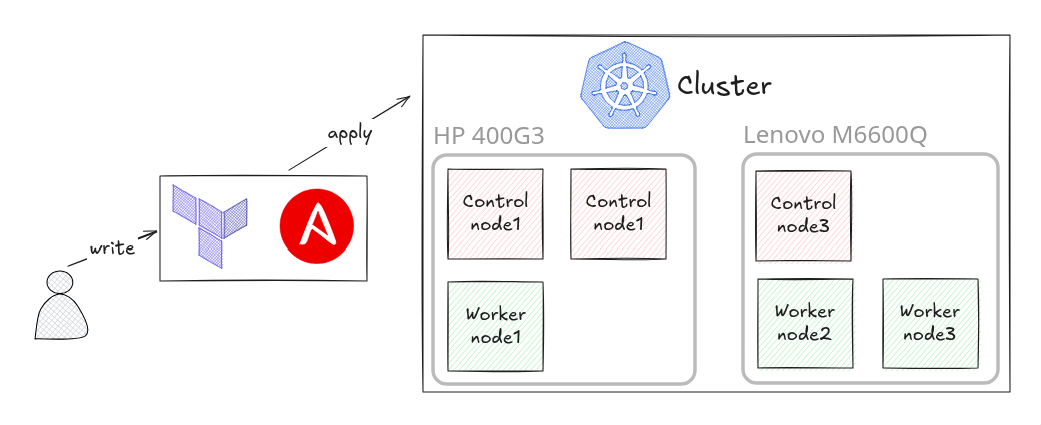

Hardware Stack:
- 3x k8s control plane node (2 on HP and 1 on Lenovo)
- 3x k8s worker nodes (1 on HP and 2 on Lenovo)
- 1x general purpose node (Rapberry Pi 5)
- 1Gbps un-managed switch for networking
Key Design Decisions:
- Used Kubeadm for cluster bootstrap
- Chose Calico for CNI (minimal overhead on resource-constrained nodes)
- Implemented etcd with local backups every 6 hours
- Used kube-apiserver behind a HAProxy load balancer
Lessons Learned
- Monitoring from day 1: Set up Prometheus + Grafana immediately to catch performance regressions
- Capacity planning matters: Running on mini-PCs taught me to optimize resource requests/limits aggressively
- Automation saves time: GitOps workflow (Flux CD) prevented manual deployment drift
- Documentation is critical: Maintained runbooks for common failure scenarios
Current State & Future Work
The cluster is now running 40+ containerized applications, with 99.7% uptime over 6 months. Future improvements include:
- Upgrade to Kubernetes 1.29 (support for more advanced security policies)
- Implement service mesh (Istio) for advanced traffic management
- Set up multi-cluster replication across different physical locations
- Automate disaster recovery testing
Conclusion
This section only for the overview of the project, to see how the cluster is set up, go to the next section.